A whirlwind tour of Kafka Summit SF 2018
2018-11-10Home
Kafka Summit San Francisco 2018 took place last month with +1200 attendees from +350 companies. All 60 talks with videos and slides side by side have been posted on Confluent's website and nicely organized in keynotes and four tracks (Pipeline, Streams, Internals and Business).
I wasn't there but I've glanced through all the slides and lingered over those I found more interesting. I'd like to share my impressions and provide a whirlwind tour of the conference. Here's an official wrap-up, by the way.
Is Kafka a Database
As you know, Kafka was born a message queue and has grown into a full-fledged streaming platform with Kafka Connect, Kafka Streams and KSQL. What else can Kafka be ? How about a database ! Martin Kleppmann argues that Kafka is a database and achieves ACID properties as in relational databases. This is mind-boggling since relation databases don't provide ACID at scale. Note that you can't set up a Kafka cluster and get ACID for free but need to carefully design your Kafka topics and streaming applications as demonstrated by the author. Still, I have some doubt over whether it can only ensure eventual consistency.
Kafka for IoT
- MQTT is a lightweight messaging protocol, built for tens of thousands of client connections in unstable network but it lacks in buffering, stream processing, reprocessing and scalability. Those're what Kafka is good at and they make a perfect match to process IoT data from end to end through Kafka Connect, MQTT Proxy or REST Proxy.
Global Kafka
-
Booking manages a global Kafka cluster with brokers spread over three zones. They have containerized replicator, Kafka connect and Kafka monitor on Kubernetes. It' worth mention that they have run into issues with distributed mode of Kafka Connect so the standalone mode is used instead.
-
Linkedin has built its own Brooklin MirrorMaker (BMM) to mirror 100+ pipelines across 9 data centers with only 9 BMM clusters. In contrast, Kafka MirrorMaker (KMM) needs 100+ clusters. Moreover, KMM is difficult to operate, poor to isolate failure and unable to catch up with traffic while BMM has dynamic configuration, automatically pausing and resuming mirroring at partition level, and good throughput with almost linear scalability.
-
To overcome the explosion of number of KMMs, Adobe introduces a routing KMM cluster to reduce the number of directly connected data center pipelines. They also have written a nice summary of their Experience Platform Pipeline built on Kafka.
Streaming platform
When Kafka Streams first came out, I was wondering why I would need another Streaming platform given the place had already been crowded with Flink, Spark Streaming, Storm, Gearpump, etc. Today it strikes me that why I would need another Streaming platform and all the workloads to set up a cluster and maintain when I can do streaming with my Kafka already there. Futhurmore, Confluent adds KSQL, a SQL interface, to relieve you of writing cumbersome codes.
-
Thus, maybe it's time to rethink stream processing with Kafka Streams and KSQL. There is an illustrative analogy between Kafka ecosystem and Unix Pipeline.
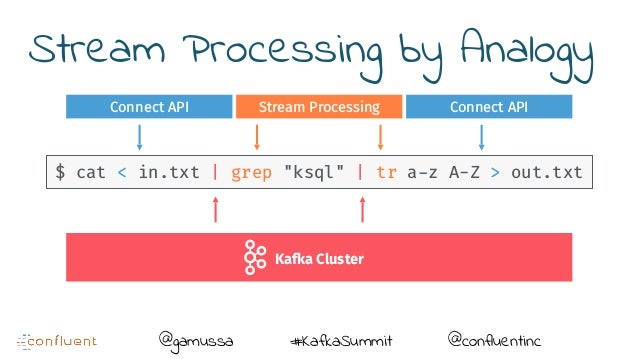
-
Stream joins are not your father's SQL joins. How joins are implemented in Kafka Streams and when to use them ? Read this zen and the art of streaming joins.
-
Companies like Booking and Braze are building their streaming pipeline around Kafka Connect (data import/export) and Kafka Streams (data processing).
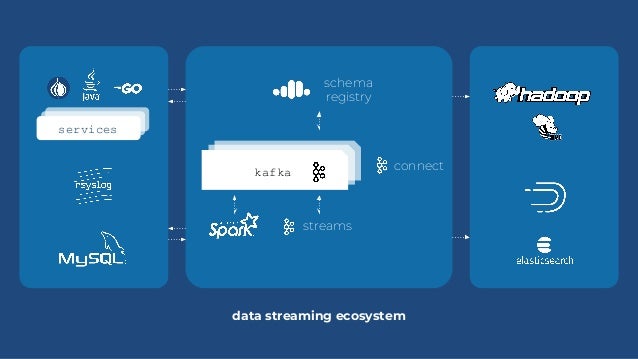
-
Change Data Capture (CDC) is a way to make use of data and schema changes of your database. Deberium is a CDC platform for various databases based on Kafka from Red Hat. Pinterest also shares their story of streaming hundreds of TBs of Pins from MySQL to S3.
Kafka on Cloud
-
Intuit have deployed Kafka on Kubernetes in production with proper configurations on load balancing, security, etc.
-
Red Hat provide an enterprise distribution of Kafka on Kubernetes/OpenShift with an open-source upstream, Strimzi. Typical Red Hat.
-
Google is not using Kafka internally but there is a demand for Kafka on Google Cloud Platform (GCP). It's interesting to learn Google's perspective on Kafka and how they fit Kafka into GCP.
-
Confluent offers some official recommendations on deploying Kafka Streams with Docker and Kubernetes.
Internals
As a developer, I love nearly every deck of the Internals track.
-
Zalando shared their War stories: DIY Kafka, especially lessons learned in backing up Zookeeper and Kafka
Backups are only backups if you know how to restore them
-
Another war story from a Kafka veteran, Todd Palino, on monitoring Linkedin's 5-trillion-message-per-day Kafka cluster. His lesson is not to monitor and alert on everything but to keep an eye on three key metrics, under-replicated partition, request handler and request timing. I totally agree with him that
sleep is best in life
-
ZFS makes Kafka faster and cheaper through improving cache hit rates and making clever use of I/O devices.
-
Jason Gustafson walked you through failure scenarios of Kafka log replication and hardening it with TLA+ model checker. ZipRecruiter is also using Chaos Engineering to level up Kafka skills.
-
Kafka is famous for using sendfile system call to accelerate data transfer. Do you know sendfile can be blocking ? I really enjoy how Yuto from Line has approached the issue from hypothesis to solution. (More details at the amazing KAFKA-7504). His analysis of long GC pause harming broker performance caused by mmap from last year is a great computer system lesson as well.
-
Who has not secured Kafka ? If you don't know the answer, then Stephane Maarek from DataCumulus offers some introductions and real-world tips. For example,

-
Uber keeps pushing for producer performance improvement without sacrificing at-least-once delivery. They shared about their best practices such as increasing replica fetch frequency and reducing thread contention and GC pauses.
Wrap-up
Kafka is definitely the backbone of companies' data architectures and serves as many as billions of messages per day. More and more streaming applications are built with Kafka Connect, Kafka Streams and KSQL. Meanwhile, quite a few companies are managing and mirroring Kafka at global scale. Finally, Kafka on Kubernetes is the new fashion.