Streaming at Spark Summit East 2016
2016-03-15Home
Spark Summit East 2016 is held in NYC last month. Databricks already had a look back, and I'm going to focus on the (Spark) streaming part here.
Highlights
The most interesting ones are
- Spark Streaming and Iot
- Online Security Analytics on Large Scale Video Survellance System
- Clickstream Analysis with Spark—Understanding Visitors in Realtime
Spark Streaming and Iot
Mike Freedman, CEO and Co-Founder of iobeam, mainly talked about the challenges in applying Spark to IoT.

I like this talk because these challenges are quite general. It's unclear how iobeam solved them with Spark Streaming which only supports data arrival time. iobeam is a data analysis platform designed for IoT. I really enjoy their websites which put codes side-by-side with use cases.
Online Security Analytics on Large Scale Video Survellance System
This is from EMC Video Analytics Data Lake, where Spark Streaming is used for online video processing and detection.
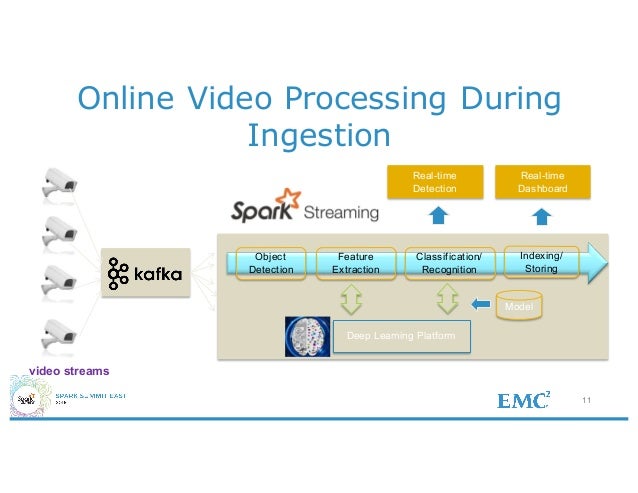
Streaming application serves to feed offline model training which is in turn used to realtime detection.
Clickstream Analysis with Spark—Understanding Visitors in Realtime
The talk is really about the architecture evolution from "Larry & Friends" (Oracle) to "Hadoop & Friends" (HDFS, Hive), from Kappa-Architecture to Lambda-Architecture, and finally Mu-Architecture all based on Spark.
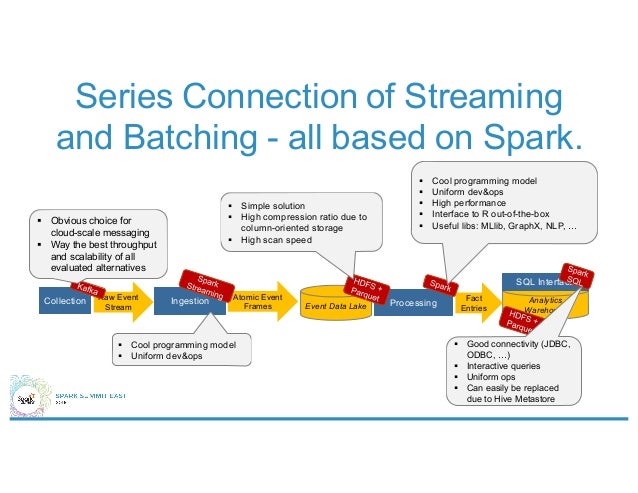
Note that realtime here means 15 mins so a low latency streaming engine like Storm is overengineered. It's, however, a sweet spot for Spark Streaming given the other components in the system are also based on Spark.
Core
Spark 2.0 will add an infinite Dataframes API for Spark Streaming, unified with the existing Dataframes API for batch processing. Event-time aggregations will finally arrive in Spark Streaming.
- The Future of Real-Time in Spark by Reynold Xin, Databricks
- Structuring Spark Dataframes, Datasets and Streaming by Michael Amburst, Databricks.
Meanwhile, Back pressure and Elastic Scaling are two important features under development.
- Reactive Streams, linking Reactive Application to Spark Streaming by Luc Bourlier, Lightbend.
- Building Robust, Scalable and Adaptive Applications on Spark Streaming by Tathagata Das, Databricks.
Connectors
- Realtime Risk Management Using Kafka, Python, and Spark Streaming at Shopify.
- Building Realtime Data Pipelines with Kafka Connect and Spark Streaming by Confluent. This is more about Kafka connnect than Spark Streaming.
Use cases
Other less interesting use cases
- Interactive Visualization of Streaming Data Powered by Spark introduces streaming data visualization at Zoomdata.
- Online Predictive Modeling of Fraud Schemes from Mulitple Live Streams at Atigeo.
- Using Spark to Analyze Activity and Performance in High Speed Trading Environments