Photon : Fault-tolerant and Scalable Joining of Continuous Data Streams
2015-07-15Home
Photon: Fault-tolerant and Scalable Joining of Continuous Data Streams - Ananthanarayanan et al. 2013
We are familar with how join is performed in a relational databases (RDBMS). A typical inner-join SQL could be
select * from t_primary, t_foreign,
where t_primary.foreign_key = t_foreign.primary_key
A naive implementation of such a query is nested-loops-joins, where outer loop consumes table t_primary row by row and inner loop executed for each outer row searchs for matching rows in table t_foreign.
Joining two continuous data streams are like joining two tables in RDBMS but with far more challenges.
- In RDBMS tables are pre-loaded while data streams are flowing into the system continuously and endlessly. We cannot wait for all the inputs being loaded.
- Another reason we cannot wait is the latency requirement. Data streams are usually from real-time applications where a query must be anwsered within a few seconds. Otherwise, the anwser would be valueless. Think about the case I asked about the traffic condition when driving home. If the system reported an hour later I would either already get home or be trapped in traffic jam !
- It should also have high throughput to serve a large number of requests.
- It's possible that streams data are delayed or unordered. The arrival order of inputs with the same key from two data streams are uncertain. In the extreme case, it may take hours or days for one input finally has its match. Then it already fails the latency requirement.
- Inputs could be lost or resent, which is ok for the Facebook favorite counts but untolerable for Amazon's purchase system. Amazon doesn't want to lose money and users don't want to be charged twice. Hence, it's critical to ensure join is performed exactly-once.
- When the data volume cannot fit into a single machine we have to scale out and shard data on many commodity machines. For one, high scalability is required as data is ever growing. For another, network partitions and hardware failures become the norm. The system should have good fault-tolerance and strike a balance between availability and consistency.
It's interesting to see how Google approaches these challenges in its joinning system, Photon, which is driving Google's Advertising System. Photon joins data streams such as web search queries and user clicks on advertisements and the joined log derives key business metrics includign billing for advertisers. It's geographically distributed and processes millions of events per minute at peak with an average end-to-end latency for less than 10 seconds.
Here's how Photon joins a search query with subsequent clicks on ads.

Photon formalizes the problem as
Formally, given two continuously growing log streams such that each event in the primary log stream contains a unique identifier, and each event in the foreign log stream contains the identifier referring to an event in the primary log stream, we want to join each foreign log event with the corresponding primary log event and produce the joined event.
As a system joinning continuous data streams, Photon face the challenges as described above. Additionally, at Google's scale, Photon is required to automatically handle datacenter-level outage with no manual operations and no impact on system availability. Hence, there are at least two copies of Photon pipeline in differenct datacenters each of which continues processing independent of the other.
While datacenter-level replication ensures availability, it becomes very difficult to guarantee consistency, i.e. one Photon pipeline should be aware whether one input event is already joined by another Photon pipeline. That means an input envent is joined at-most-once. Photon relies on its IdRegistry, a Paxos based in-memory key-value store, to coordinate between pipeline workers. Let's see how it works through an illustration of a single Photon pipeline.
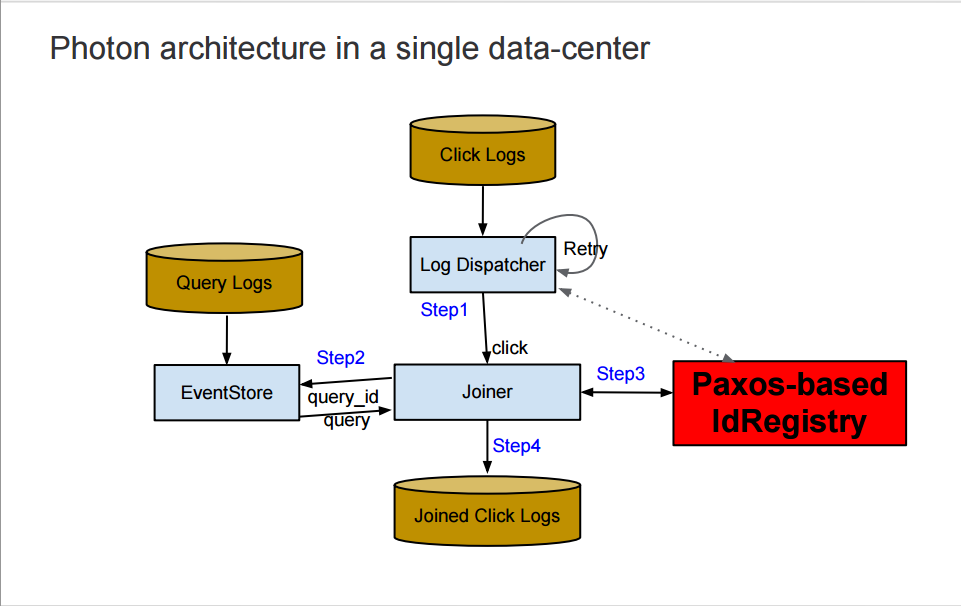
- The dispatcher consumes the click events from the logs as they come in, and issues a lookup in the IdRegistry. If the click id already exists in the IdRegistry, the dispatcher assumes that the click has already been joined and skips processing the click.
- If the click id does not exist in the IdRegistry, the dispatcher sends the click to the joiner asynchronously and waits for the response. If the joiner fails to join the click (say, due to a network problem, or because of a missing query event), the dispatcher will keep retrying by sending the click to another joiner instance after some backoff period. This guarantees at-least-once semantics with minimum losses.
- The joiner extracts query id from the click and does a lookup in the EventStore to find the corresponding query.
- If the query is not found, the joiner sends a failure response to the dispatcher so that it can retry. If the query is found, the joiner tries to register the click id into the IdRegistry.
- If the click id already exists in the IdRegistry, the joiner assumes that the click has already been joined. If the joiner is able to register click id into the IdRegistry, the joiner stores information from the query in the click and writes the event to the joined click logs.
The retrying logic ensures an input event is joined at-least-once. Combined with the at-most-once semantics guaranteed by IdRegistry, an input event is joined exactly-once in Photon. The system now looks reaonable and functional but it still needs to be performant, which highly depends on the performance of IdRegistry.
To be fault-tolerant, IdRegistry is itself replicated in different geographical regions.
Based on typical network statistics, the round-trip- time between different geographical regions (such as east and west coasts of the United States) can be over 100 milliseconds. This would limit the throughput of Paxos to less than 10 transactions per second, which is orders of magnitude fewer than our requirements—we need to process (both read and write) tens of thousands of events (i.e., key commits) per second.
To improve IdRegistry's throughput,
- only meta-data is stored in IdRegistry.
- batches client-side requests into one .
- batches server-side operations into one Paxos transaction.
- dynamically shards IdRegistry such that operations on different shards are performed concurrently.
- deletes old keys
Events delayed by more than N days are discarded where N is determined by evaluating the trade-off between the costage of storage of the cost of dropping such events.
This post is inspired by The Morning Paper.